|
Getting your Trinity Audio player ready...
|
The mobile app landscape is undergoing profound changes. As expectations of the users increase and digital experiences become more personal, app developers and product owners are racing to add artificial intelligence (AI) to their apps. But all types of AI are not the same. In 2025, a new wave of implementing AI is being propulsive—Retrieval-Augmented Generation (RAG).
Whether you are building an assistant, a content discovery engine, or an intelligent recommendation engine, RAG combines the accuracy of real-time data with the fluidity of dialogue-style responses.
So, what is RAG exactly? Why is it emerging in bleeding-edge mobile applications? As product owners and technical leaders, how can we capitalise on this ability to develop better, smarter applications? This guide is going to help you understand and use this technology.
Let’s look at how RAG is changing the scene in interactions between mobile apps and their users and why now is the perfect time to start thinking about putting it into your mobile product plan.
Understanding RAG: A Breakdown
For anyone desiring a more nuanced view of RAG, it must be understood in terms of its internal mechanics.
What is RAG?
Retrieval-augmented generation, a cutting-edge technique for processing natural language, combines retrieval-based systems and generative language models. Essentially, it involves an AI model retrieving relevant documents from the knowledge base and subsequently generating a precise human contextual answer.
Short History
Apps employed:
Keyword search systems: Swift but rigid, giving exact returns with no context understanding.
Generative models (like GPT): More fluent and conversational used but sometimes inaccurate or hallucinated when lacking knowledge of current events.
That was before. Now, RAG combines both elements. It uses augmented generative models incorporating real-time retrieval of knowledge so that the system’s minimal human-simulating operation more closely resembles that of a typical librarian in execution.
Two Major Building Blocks of RAG
The Retrieval Module
This module’s function is to find the most pertinent documents or data entries. It generally uses:
- Vector embeddings (a numerical representation of meaning in a text)
- Semantic search engines, like FAISS and Pinecone, or Weaviate.
There is a document store or knowledge base from which such documents/knowledge can be derived. These are product manuals, blogs, or customer FAQs.
The Generation Module
Once documents are retrieved, the language model (OpenAI GPT, Anthropic Claude, etc.) will use that context to synthesise a response based on the user’s query.
Very Simplistic Analogy:
RAG is basically a Google Search + ChatGPT hybrid. When you ask a question, it first retrieves the most pertinent source of information (like Google searching) and then explains it in a friendly conversational fashion (like ChatGPT). It’s like having a smart librarian and a gifted writer working together: the first finds the facts and the second spins them into a story.
Use Cases of RAG in Mobile Apps
It does not possess an extraordinary ability to predict the future. Instead, it has been supporting mobile applications across various industries. Here are some of the practical use cases of RAG that provide clear benefits it can deliver.
Smarter In-App Search
The time for a simple keyword search has elapsed. RAG offers a semantic and context-oriented search that understands user intent. For instance, a user may not just type in “best shoes”; he may rather ask, “which shoes are best for long mountain trails?” and RAG would come up with the perfect answer.
AI-Powered Chat Assistants
Customer service chatbots quite often become futile because of their static replies. RAG lends chat assistants the ability to retrieve live information from up-to-date knowledge bases, thus furnishing precise and very relevant responses in a dialogue-orientated fashion.
Example: For a fintech app, using RAG could allow it to answer, “How do I dispute a transaction made last week?” The procedure could involve citing the latest company policy and generating a step-by-step guide.
Knowledge-Heavy Apps
These applications are often legal, medical, and educational, requiring high accuracy and contextual response. RAG is powered to provide reliable, dynamic answers based on actual case law, medical journals, or curated databases.
Example: A law app can answer, using current legal documents—and not old texts—”What are the tenant rights in New York for 2025?”
Personalized E-Commerce Recommendations
RAG is able to recommend products in a more human context after analysing search queries and browsing histories. Rather than just saying, “Recommended for you” based on tags, RAG could say, “Since you liked hiking boots, you might want to check these trail backpacks that match your terrain preference.”
Personalized Content Generation
News, blogs, or fitness platforms might generate tailor-made content for users. Powered by RAG, a fitness app may generate a custom seven-day meal plan or summarise news articles about a chosen topic in real time.
Benefits of Integrating RAG into Your Mobile App
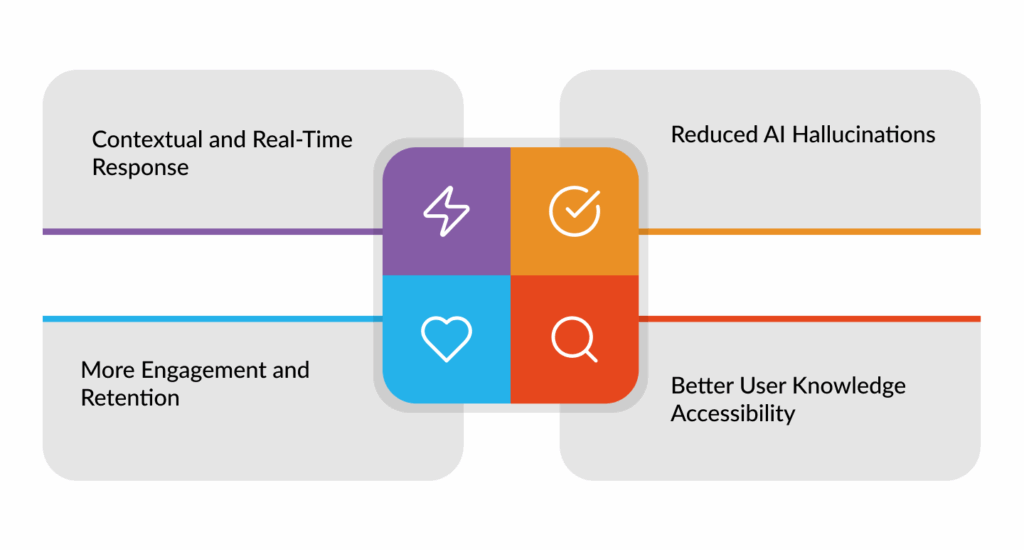
Contextual and Real-Time Response
Traditional models rely predominantly on static training data. RAG, conversely, brings in the most up-to-date knowledge; hence, users receive answers that are based on current facts, making it an ideal solution in fast-moving industries such as finance, healthcare, and education.
Reduced AI Hallucinations
RAG minimises its chances of generating false or misleading information by linking its responses to the retrieved content. This process builds trust and credibility, particularly in customer support, compliance, and health apps.
More Engagement and Retention
An app that responds intelligently brings more and more users back again. Whether it is a chatbot that actually solves users’ problems or a piece of content that adapts to user interests, RAG enhances satisfaction and the “stickiness” factor.
Better User Knowledge Accessibility
Users do not have to know how to phrase their queries perfectly. They can ask natural, messy questions, and RAG will interpret, retrieve, and respond intelligently. This particular feature reduces friction and enhances usability.
How to Integrate RAG into a Mobile App
While RAG might sound complex, the integration process can be broken into manageable steps. Here’s a high-level overview.
Step-by-Step Process
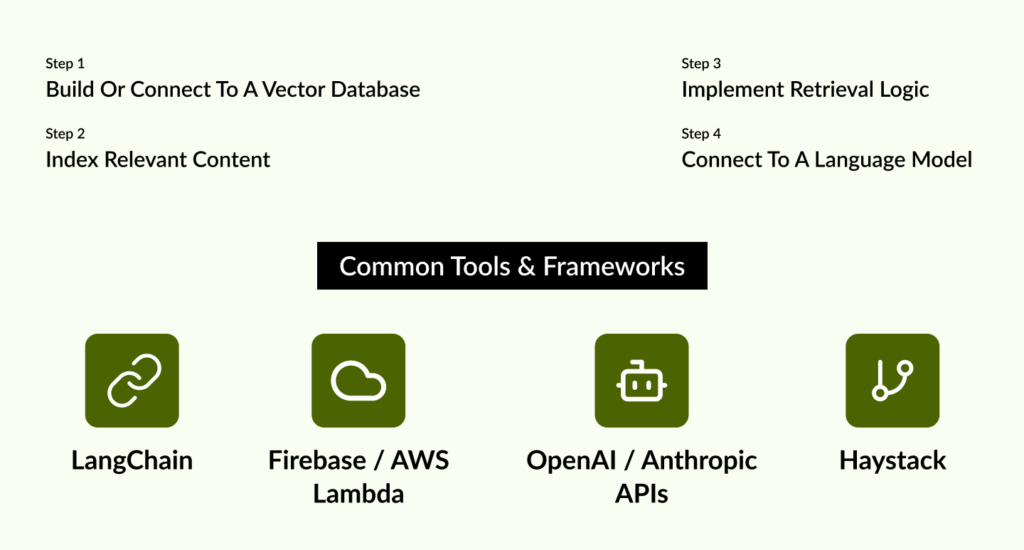
Step 1: Build or Connect to a Vector Database
Start by setting up a vector storage system where content (documents, FAQs, blogs, etc.) is converted into embeddings and stored.
Recommended tools:
- Pinecone
- FAISS
- Weaviate
Step 2: Index Relevant Content
Transform your app’s content—product details, customer guides, support articles—into vector embeddings using models like OpenAI’s text-embedding-ada-002.
Step 3: Implement Retrieval Logic
Use semantic search to fetch relevant chunks based on user queries. This method ensures high precision, even when queries are phrased differently.
Step 4: Connect to a Language Model
Send the user’s query and the retrieved documents to an LLM (e.g., GPT-4 via OpenAI API). The model will generate a response that integrates both the query and the supporting data.
Common Tools & Frameworks
- LangChain – Ideal for chaining retrieval and generation steps
- Firebase / AWS Lambda – For backend logic in mobile apps
- OpenAI / Anthropic APIs – For accessing state-of-the-art LLMs
- Haystack – For building full-fledged RAG pipelines
Challenges to Consider
Any sophisticated system comes with its set of challenges perfectly positioned for a smooth consideration and adoption plan in mobile implementations of RAG.
Data Privacy & Security
Such factors are indispensable if any sensitive information is involved (like health data and legal documents), in which an appropriate solution of data encryption controls over access and data anonymisation needs to be enforced. Retrieval modules must also conform to laws such as GDPR and HIPAA.
Latency Optimization
Since RAG has to retrieve and generate, there is an implicit time taken. Low-latency designs and implementations, especially on mobile, mean investing wisely in infrastructure, caching, and sometimes computation on mobile.
Picking the Right Infrastructure
Should it be serverless? Cloud-embedded? Edge-based? All that matters is the cost, latency, and scalability scenarios. When it comes to mobile apps, they should be lightweight and seamless, which is why architecture is crucial.
Cost Control
Vector databases, embedding generation, and LLM API calls can be costly at scale. Cost control can be maintained by employing batching, caching, and hybrid models in which some data is fetched locally.
Esferasoft’s Expertise in RAG & AI-Powered Mobile App Development
Esferasoft has been at the forefront of intelligent app development, with years of experience in NLP, GenAI, and custom mobile solutions.
Use-Case Identification
We don’t just implement RAG—we help you identify the highest-impact opportunities within your app. Whether you improve support, personalise content, or build an AI assistant, we’ll make sure the investment aligns with your goals.
Technical Implementation
Our engineers specialise in:
- Custom vector DB setups
- LangChain + OpenAI integrations
- Mobile backend optimization
- UX/UI for AI-powered interactions
End-to-End Support
From early PoCs (proofs of concept) and MVPs to full production rollouts, we provide ongoing support, testing, and optimisation. We also train your team on how to manage and maintain the RAG ecosystem post-deployment.
Conclusion
The way users interact with mobile apps is evolving—and so should the technology behind them. In a time where relevance, accuracy, and immediacy define user experience, Retrieval-Augmented Generation (RAG) offers a distinct edge.
Unlike traditional AI systems that rely solely on static data, RAG brings agility and intelligence together. It enables your app to think fast and respond smarter, pulling in the latest information and crafting answers that feel human, not robotic. Whether you’re improving customer support, tailoring user recommendations, or delivering dynamic content, RAG turns every interaction into a more informed and meaningful one.
But building a RAG-powered app isn’t just about plugging in APIs. It’s about aligning technical capabilities with business goals, choosing the right infrastructure, and ensuring seamless user experiences. That’s where we come in.
From defining use cases and integrating robust retrieval pipelines to deploying scalable AI-powered features, we help product owners and tech leaders bring intelligent mobile solutions to life—without the guesswork.
If you’re serious about building apps that not only respond—but truly understand—let’s make it happen.
Get in touch with us today at +91 772-3000-038 and discover how RAG can redefine what your app delivers.


